Many organisations believe they are ready for AI because they have data.
Customer data. Sales data. Service data. Finance data. Product data. Operational data. Documents. Reports. Emails. Call transcripts. Policies. Knowledge articles. Spreadsheets. CRM records. ERP records. Website analytics. Support tickets. Meeting notes.
The data exists somewhere.
But data availability is not the same as data readiness.
This is one of the most important distinctions leaders need to understand before starting an AI project.
Table of Contents
An organisation may have large volumes of data, but that data may not be complete, accurate, accessible, current, consistent, governed, structured, trusted or fit for the specific AI use case. It may sit across different systems. It may be owned by different teams. It may use inconsistent definitions. It may be duplicated. It may contain outdated information. It may be stored in formats that are difficult to use. It may lack the context required for AI to interpret it properly.
When these issues are ignored, AI projects struggle.
The model may produce poor outputs.
Users may not trust the results.
Governance teams may block deployment.
The pilot may work in a narrow test but fail in real operations.
The project may require more cleanup and redesign than expected.
The business may lose confidence before value is realised.
This is why data readiness can make or break AI projects.
AI does not only depend on algorithms, models or tools. It depends on the information foundation underneath them. If that foundation is weak, the AI project inherits the weakness.
Data Problems Are Often Business Problems
Data readiness is often treated as a technical issue.
It is not only technical.
Data quality reflects how the organisation works.
If customer records are incomplete, that may reflect process gaps in sales, service or onboarding.
If product information is inconsistent, that may reflect unclear ownership between product, marketing, e-commerce, operations and finance.
If support tickets are poorly categorised, that may reflect rushed service workflows, unclear taxonomy or weak manager reinforcement.
If policies are outdated, that may reflect poor document governance.
If different teams define the same metric differently, that may reflect fragmented decision-making and weak data standards.
If important knowledge sits in people’s heads, inboxes or private spreadsheets, that may reflect informal workarounds that have become part of the operating model.
In other words, data issues are often symptoms of process, governance, accountability and behaviour issues.
AI makes these issues visible because it depends on the organisation’s knowledge and data being usable at scale.
A person can often work around messy information. They can ask a colleague, interpret a spreadsheet, remember an exception, or apply judgement based on experience.
AI cannot reliably compensate for unclear ownership, inconsistent definitions or poor-quality inputs unless the system is specifically designed to manage those limitations.
That is why leaders should not ask only, “Do we have the data?”
They should ask, “Is our data ready for the decision, workflow or output we expect AI to support?”
The Difference Between Data Availability And Data Readiness
Data availability means the data exists.
Data readiness means the data is suitable for use in a specific AI-enabled business context.
This distinction matters because many AI projects begin with a false assumption:
“We already have the data, so this should be straightforward.”
That may or may not be true.
For example, an organisation may have thousands of customer service tickets. But if categories are inconsistent, issue descriptions are incomplete, resolution notes are vague, customer outcomes are not captured, and escalation reasons are unclear, the data may not be ready to train or evaluate an AI triage system.
A business may have years of sales data. But if opportunity stages are used differently by different teams, close dates are unreliable, lost reasons are missing, and CRM activity is incomplete, the data may not be ready for AI-driven pipeline risk analysis.
A company may have a large library of internal documents. But if policies are duplicated, outdated, contradictory or poorly tagged, the organisation may not be ready for a trusted AI knowledge assistant.
Data readiness is use-case specific.
The same data set may be good enough for one AI use case but not another.
A lightly governed knowledge base may be acceptable for low-risk internal drafting support. It may not be acceptable for customer-facing responses, compliance advice or safety-related decision support.
That is why data readiness should be assessed in relation to the business problem, workflow, risk level and expected AI output.
Why Poor Data Readiness Damages Trust
AI adoption depends on trust.
Users need to trust that the AI output is useful, relevant and safe enough to apply in their work. They do not need to believe the AI is perfect, but they do need to understand its limits and have confidence in the process around it.
Poor data readiness damages that trust quickly.
If an AI assistant gives outdated answers, users will stop relying on it.
If a recommendation engine suggests actions based on incomplete data, managers will question its value.
If an AI agent routes cases incorrectly because categories are unclear, frontline teams will work around it.
If generated content uses old product information, teams will return to manual checking.
If an AI dashboard produces numbers that do not match existing reports, executives will lose confidence.
Trust is hard to build and easy to lose.
Once users experience unreliable outputs, it can be difficult to convince them to try again, even after the underlying data has been fixed.
This is why data readiness should be addressed before adoption is damaged.
It is better to narrow the first use case, improve the data foundation, define human review points and set realistic expectations than to launch broadly with weak inputs and lose user confidence.
In AI transformation, trust is not created by enthusiasm. It is created by evidence, governance, reliability and useful experience.
Data readiness is central to all four.
Data Readiness Shapes The AI Use Case
Data readiness should not be assessed after the use case has already been locked in.
It should shape the use case itself.
If the data is strong, the organisation may be able to pursue a more ambitious AI solution.
If the data is weak, the use case may need to be narrowed, staged or redesigned.
For example, an organisation may want an AI agent to automatically respond to customer enquiries. During assessment, it discovers that product information is inconsistent, service policies are outdated, and escalation rules differ across teams.
A full automated response agent may not be ready.
But a narrower use case may still be valuable.
AI could summarise enquiries, suggest likely categories, retrieve draft knowledge references and route cases to human agents for review. In parallel, the organisation could clean product content, clarify service rules and improve knowledge ownership before expanding automation.
This staged approach does not mean the AI project has failed.
It means the organisation has aligned the solution to its readiness level.
Another example: a business may want predictive demand forecasting. But if historical demand data is inconsistent, promotional periods are not properly labelled, stockouts are not captured, and external factors are missing, the first phase may need to focus on data preparation and forecasting for a limited product category.
Good AI solution framing responds to data reality.
Poor AI solution framing ignores data reality and then discovers it during implementation.
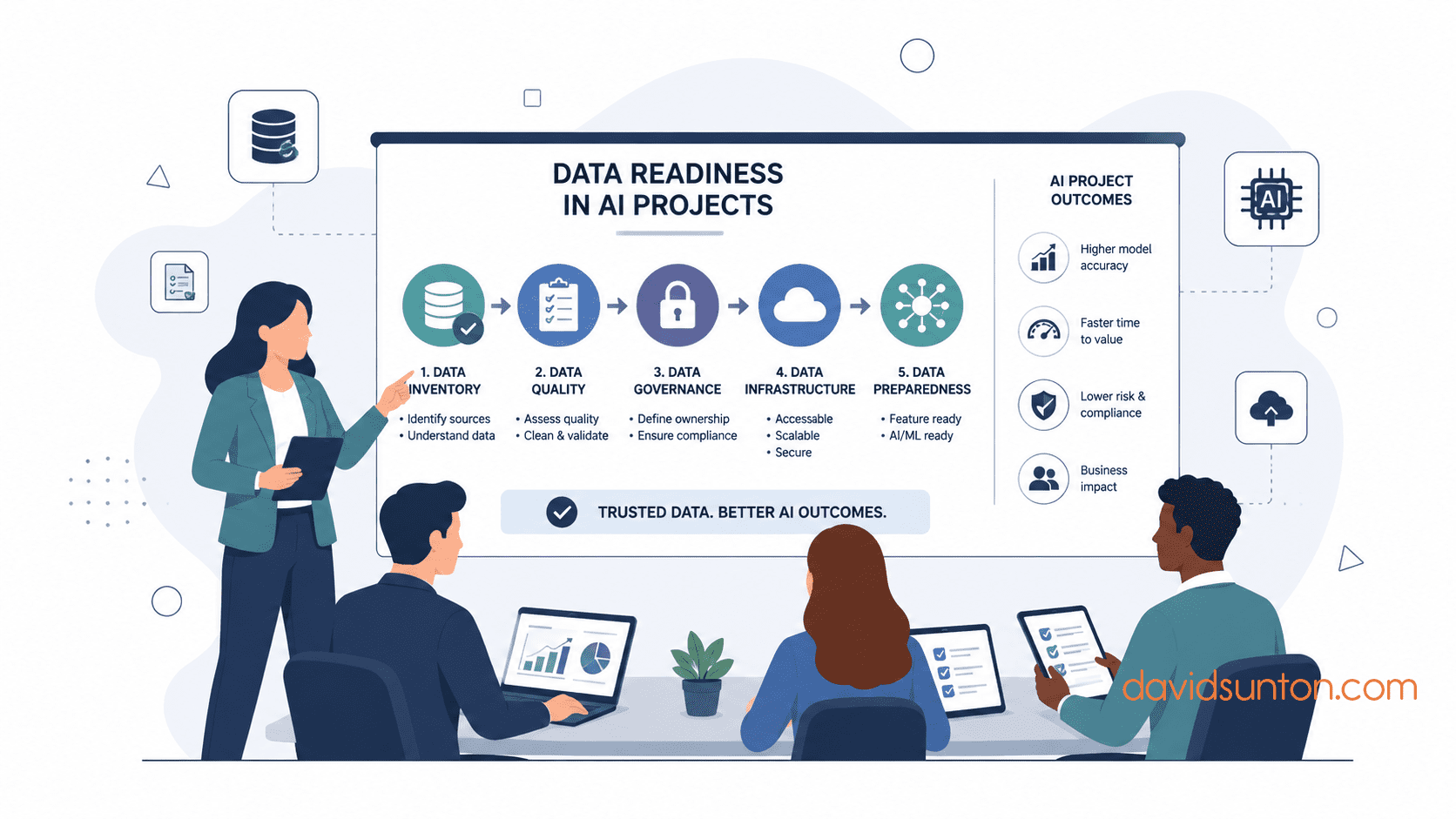
The Core Dimensions Of Data Readiness
Leaders do not need to become data engineers to ask better data readiness questions.
They need a practical way to assess whether the data is fit for the intended AI use case.
Several dimensions matter.
1. Availability
Does the required data exist?
This is the most basic question, but it should not be skipped.
Leaders need to identify what data the AI use case requires and whether it actually exists in a usable source.
For a customer service AI use case, required data might include enquiry history, case categories, resolution notes, product information, customer records, escalation rules and knowledge articles.
For a sales AI use case, required data might include CRM activity, opportunity stages, meeting notes, proposal history, deal values, customer segments and win-loss reasons.
For an internal knowledge assistant, required data might include policies, procedures, training documents, process guides, FAQs and approved reference material.
The key is to identify the specific data required for the use case, not simply assume the organisation has “lots of data.”
2. Accessibility
Can the data be accessed safely and practically?
Data may exist but still be difficult to use.
It may sit in legacy systems. It may be locked behind permissions. It may be spread across multiple platforms. It may require manual exports. It may be owned by different teams. It may contain sensitive information. It may not be accessible through APIs or integration points.
Accessibility should include technical access, permission access and operational practicality.
If the AI solution needs real-time data but the organisation can only export spreadsheets weekly, the design needs to account for that limitation.
If the data includes personal or confidential information, access must be governed properly.
If multiple systems are involved, integration effort may affect feasibility, cost and timing.
Data access is not just a technical detail.
It can determine whether a use case is practical.
3. Quality
Is the data accurate, complete and consistent enough?
Data quality is one of the most common barriers to AI success.
Leaders should ask whether the data contains errors, missing fields, duplicates, outdated records, inconsistent labels or unreliable entries.
Quality does not need to be perfect for every use case. The required level of quality depends on the risk and purpose of the AI output.
A low-risk summarisation tool may tolerate some imperfections if humans review the output.
A compliance monitoring system or customer-facing AI agent may require much stronger quality controls.
The question is not, “Is the data perfect?”
The question is, “Is the data good enough for this use case, with the right controls?”
4. Context
Does the data include enough meaning for AI to use it properly?
Data without context can be misleading.
A support ticket category may not explain why the case was routed a certain way.
A lost sales opportunity may not explain whether the customer chose a competitor, delayed the project, lacked budget or disliked the proposal.
A policy document may not explain which version is current or which business unit it applies to.
A stock movement record may not explain whether demand was genuine, promotional, seasonal or distorted by stockouts.
AI systems need context to produce useful outputs.
For generative and retrieval-based AI, context may include metadata, document ownership, update dates, approval status, business unit relevance and source reliability.
For predictive AI, context may include labels, events, time periods, exceptions and external factors.
Without context, AI may find patterns that are technically present but operationally misleading.
5. Governance
Who owns the data and keeps it reliable?
Data readiness is not only about preparing data for launch. It is about keeping data reliable over time.
Leaders should ask:
Who owns the data source?
Who approves updates?
Who removes outdated content?
Who resolves conflicts between sources?
Who monitors quality?
Who defines access rules?
Who is accountable if the AI uses the wrong information?
This is especially important for AI knowledge assistants and retrieval-augmented systems. If the AI depends on internal documents, someone must own the content lifecycle.
Without governance, today’s accurate answer can become tomorrow’s outdated answer.
AI needs a living information foundation, not a one-time data upload.
6. Security And Privacy
Can the data be used within the right boundaries?
AI data readiness must include privacy, security and confidentiality.
Leaders need to understand what information the AI can access, what it can process, what it can retain, who can see outputs, and what controls are required.
Some data may include personal information, customer records, employee information, commercial secrets, health information, financial records or confidential business material.
For these use cases, the organisation must define appropriate safeguards.
This may include access controls, masking, data minimisation, audit logs, retention rules, human review, approved environments and clear usage policies.
Security and privacy cannot be added as an afterthought.
They shape whether the AI use case can proceed and how it should be designed.
7. Timeliness
Is the data current enough?
Some AI use cases depend heavily on current information.
A customer-facing knowledge assistant needs up-to-date product, policy and service information.
An inventory recommendation system needs current stock and demand data.
A sales pipeline tool needs recent activity and opportunity updates.
A risk monitoring system needs timely transaction or operational data.
If the data is stale, the AI output may be misleading.
Timeliness is not only about refresh frequency. It is also about process discipline.
How quickly do teams update records?
How often are documents reviewed?
How are outdated sources removed?
How are urgent changes reflected in the AI environment?
The more time-sensitive the use case, the more important data freshness becomes.
8. Fit For Workflow
Does the data support the actual decision or action?
Data may be accurate but still not fit for the workflow.
For example, a report may provide monthly averages when the operational decision requires daily exception alerts. A customer record may include contact details but not the service history needed for triage. A product database may include descriptions but not the warranty rules needed for support. A CRM may include opportunity value but not the relationship signals needed for account prioritisation.
Fit for workflow means the data supports the task AI is expected to perform and the decision humans need to make.
This is where data readiness connects directly to process design.
Leaders should ask not only whether the data is good, but whether it is useful at the point of work.
Example: Data Readiness In An AI Knowledge Assistant
Consider an organisation that wants to deploy an internal AI knowledge assistant.
The ambition is simple: employees should be able to ask questions and receive accurate answers based on internal policies, procedures, templates and process documents.
The use case sounds practical.
But data readiness determines whether it will be trusted.
The organisation needs to assess:
Are the relevant documents available?
Are they stored in one location or scattered across drives, intranets, emails and team folders?
Are there duplicate versions?
Which documents are current?
Who owns each policy or procedure?
Are documents written clearly enough for retrieval?
Are access permissions appropriate?
Are some documents confidential or role-specific?
How often will content be reviewed?
What happens when policy changes?
Who will monitor answer quality?
If these questions are not answered, the AI assistant may provide outdated, incomplete or conflicting responses.
Users may try it once, receive a poor answer and stop using it.
The problem will not be that AI is incapable.
The problem will be that the organisation’s knowledge foundation was not ready.
A better approach would be to prepare the knowledge base first: identify approved sources, remove duplicates, assign owners, clarify permissions, improve metadata, define update routines and start with a limited set of high-value topics.
This creates a stronger foundation for adoption.
Example: Data Readiness In Predictive AI
Now consider an organisation that wants to use AI to forecast demand.
The business wants better inventory planning, fewer stockouts, reduced excess stock and improved cash flow.
Again, the opportunity may be strong.
But data readiness is critical.
The organisation needs to assess:
Is historical sales data complete?
Are stockouts recorded, or do they appear as low demand?
Are promotions labelled?
Are price changes captured?
Are product substitutions understood?
Are seasonal effects visible?
Are discontinued products handled correctly?
Are returns and cancellations included?
Are external factors relevant?
Are product hierarchies consistent?
If the AI model is trained on incomplete or misleading historical data, the forecast may appear precise but produce poor decisions.
For example, if stockouts are not captured, the model may interpret low sales as low demand rather than lack of availability. If promotions are not labelled, the model may misread temporary demand spikes as normal patterns.
This is why data readiness is not just about volume.
It is about whether the data correctly represents the business reality the AI is trying to learn from.
Data Readiness And Human-In-The-Loop Design
Data readiness also affects human-in-the-loop design.
If data quality is uncertain, human review becomes more important.
If the data is strong and the risk is low, the workflow may allow more automation.
If the data is weak or the decision is high impact, the AI should support human judgement rather than act independently.
For example, if an AI tool extracts information from supplier invoices but the source documents vary in quality, the system may route low-confidence extractions to human review. If the AI recommends customer responses based on a knowledge base that is still being improved, higher-risk responses may require approval before being sent.
The level of human involvement should reflect the readiness of the data and the risk of the decision.
This is why data readiness, governance and workflow design should be assessed together.
Human-in-the-loop is not just a safety principle.
It is a practical design response to uncertainty.
Data Readiness Should Shape The Pilot
AI pilots should not only test whether the technology works.
They should test whether the data is ready enough for the use case.
A good pilot should answer questions such as:
Does the AI produce useful outputs from our actual data?
Where does the data fail?
Which fields are missing or unreliable?
Which documents produce poor answers?
Which categories are unclear?
Which exceptions appear frequently?
How much human review is required?
What needs to be cleaned, governed or redesigned before scaling?
This creates learning that is directly relevant to implementation.
A weak pilot uses clean sample data and proves only that the technology can work in theory.
A stronger pilot uses realistic data and reveals whether the organisation is ready to operationalise the use case.
The goal is not to hide data problems during the pilot.
The goal is to discover them early enough to act.
What Leaders Should Do Before Starting The AI Project
Before starting an AI project, leaders should run a practical data readiness assessment.
This does not need to be overly complex, but it should be specific to the use case.
First, define the AI use case clearly.
The data readiness question cannot be answered in the abstract. It depends on what the AI is expected to do.
Second, identify the required data sources.
List the systems, documents, records, knowledge bases, transcripts, emails, files or databases that the use case depends on.
Third, assess quality and gaps.
Look for missing fields, outdated documents, inconsistent definitions, duplication, access issues, weak labels and unclear ownership.
Fourth, assess risk and sensitivity.
Identify personal, confidential, regulated or commercially sensitive data. Define what can be used, by whom and under what controls.
Fifth, assess workflow fit.
Check whether the data supports the actual decision, recommendation, response or action the AI is expected to support.
Sixth, define ownership.
Assign responsibility for maintaining the data, resolving conflicts, approving updates and monitoring quality.
Seventh, shape the scope.
If data readiness is weak, narrow the use case, stage the rollout, add human review, or complete data preparation before implementation.
Eighth, build feedback loops.
Once the AI is live, users should be able to flag poor outputs, outdated information and data gaps so the system continues to improve.
This approach helps leaders avoid one of the most common AI project traps: discovering data problems only after implementation has begun.
Data Readiness Is A Leadership Responsibility
Because data readiness is often technical, leaders may be tempted to delegate it entirely to data or IT teams.
That is a mistake.
Technical teams can assess systems, pipelines, access, formats and integration. But business leaders must help define meaning, ownership, workflow relevance, risk tolerance and decision context.
A data team may know whether a field exists.
The business needs to explain whether the field is meaningful.
A technology team may know whether documents can be indexed.
The business needs to confirm which documents are approved, current and trustworthy.
A data engineer may know whether customer records are complete.
The process owner needs to explain why records are incomplete and what behaviour must change.
Data readiness therefore requires shared ownership across business, technology, governance and change leadership.
Leaders do not need to solve every data issue themselves. But they do need to sponsor the organisational discipline required to make data usable.
AI-ready data is not created by technology alone.
It is created by clear ownership, good process, governance, accountability and consistent behaviour.
The Risk Of Skipping Data Readiness
When organisations skip data readiness, several problems appear.
Projects take longer than expected because data cleanup becomes an unplanned workstream.
Scope expands because hidden data issues create new dependencies.
Outputs disappoint users because the AI is working from weak inputs.
Governance teams delay approval because access, privacy or ownership is unclear.
Costs increase because integration and preparation are more complex than assumed.
Pilots fail to scale because they were tested on narrow or artificial data.
Adoption suffers because users do not trust the system.
Benefits are not realised because the AI does not fit real operational conditions.
These problems are avoidable if data readiness is assessed early.
The assessment may reveal that the use case is ready to proceed. It may reveal that it needs a narrower scope. It may reveal that data preparation should happen first. It may reveal that a different use case should be prioritised.
All of these outcomes are valuable.
They help the organisation make better decisions before committing too heavily.
Data Readiness Does Not Mean Waiting For Perfect Data
One final point matters.
Data readiness does not mean waiting until all data is perfect.
If organisations waited for perfect data, many AI initiatives would never begin.
The goal is to understand whether the data is good enough for the use case, with the right design, controls and expectations.
A staged approach can be effective.
Start with a narrow process.
Use approved data sources.
Add human review.
Limit the risk exposure.
Measure output quality.
Collect user feedback.
Improve the data foundation over time.
Expand once trust and readiness improve.
This is often more practical than trying to solve every data issue upfront.
The key is honesty.
Leaders need to know where the data is strong, where it is weak, what controls are required and what assumptions are being made.
AI projects do not need perfect data.
They need data readiness that matches the ambition, risk and workflow of the use case.
Final Thought
Data readiness can make or break AI projects because AI is only as useful as the information foundation it depends on.
Having data is not enough.
The data must be available, accessible, accurate enough, current enough, governed, secure, contextual and fit for the workflow.
More importantly, the organisation must understand that data readiness is not only a technical task. It is a business discipline.
It reflects how work is done, how information is maintained, how decisions are made, how ownership is defined and how governance is enforced.
Before leaders ask, “Which AI solution should we implement?” they should ask:
“Is our data ready for the AI use case we want to pursue?”
That question can prevent wasted effort, reduce implementation risk, improve adoption and build trust.
AI transformation does not start with the model.
It starts with the business problem, the process and the information foundation required to solve it well.